 ISSN 2321-4635
ISSN 2321-4635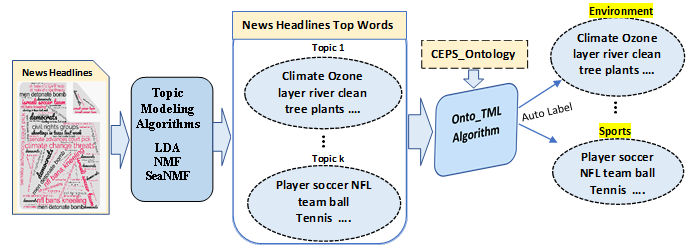
Onto_TML: Auto-labeling of topic models
Abstract
Text mining is a new branch of AI that employs natural language processing techniques to convert unstructured text into a structured format for easier comprehension. It is becoming increasingly significant in practically every field since it allows users to extract information from large amounts of text or unstructured data. Topic modelling is one of the most important tools in text mining. Topic modelling aids in the discovery of hidden topics, which are the patterns of co-occurring words. Its purpose is to uncover hidden topics in massive amounts of unstructured data. However, because the topics detected are a list of the top n words in a topic, they may not give the viewer with a highly coherent image of the document. As a result, automatic topic labelling has been investigated in order to improve understanding of the topics. In this article we propose a novel method Onto_TML; ontology based auto-labelling for topic modelling algorithms and domain specific CEPS_ontology. Protégé tool is used to design CEPS_Ontology, comprises of four domains: Crime, Environment, Politics and Sports. Onto_TML uses CEPS_Ontology to assign appropriate generic label to the top words generated by topic modelling algorithms. For experimentation we have used two datasets News Headline dataset and News Category V-2 dataset and LDA, NMF and SeaNMF topic modeling algorithms. Empirical evaluation shows that Onto_TML has generated appropriate labels for the top words given by topic modeling algorithms
Keywords
Topic Modeling; Auto-Labeling; Ontology; Text Mining; Natural Language Processing;